In un mercato tecnologico che negli ultimi due anni è stato ossessionato dalla forza bruta computazionale e dall'accumulo di hardware, Google Research ha presentato una soluzione che sposta l'asse della competizione dall'hardware al software. TurboQuant, l'ultimo algoritmo di compressione sviluppato a Mountain View, promette di risolvere uno dei principali colli di bottiglia dell'AI generativa: l'occupazione massiccia di memoria RAM.
Mentre l'industria si scontrava con la scarsità di chip e i costi esorbitanti dell'energia, questa innovazione dimostra che l'ottimizzazione algoritmica può generare efficienza senza compromettere la qualità dell'output, un fattore che gli analisti finanziari definiscono già come il "momento DeepSeek" di Google.
La meccanica di TurboQuant di Google: PolarQuant e correzione QJL
Il cuore del sistema risiede nella gestione della "key-value cache", ovvero la memoria di lavoro che i modelli di linguaggio (LLM) utilizzano per "ricordare" il contesto durante una conversazione. Tradizionalmente, queste informazioni sono memorizzate tramite vettori in coordinate cartesiane (XYZ). Google ha introdotto PolarQuant, un metodo che converte questi vettori in coordinate polari.
Invece di processare molteplici variabili spaziali, il sistema si concentra su due soli dati: il raggio (la forza del dato) e la direzione (il significato semantico). Per eliminare i residui di errore derivanti da questa compressione, viene applicato il Quantized Johnson-Lindenstrauss (QJL), un layer di correzione a 1 bit che riduce ogni vettore a un valore di 1$, stabilizzando i punteggi di attenzione del modello.
I numeri del salto prestazionale e i dati ufficiali
I test condotti su modelli open-source come Gemma e Mistral indicano che TurboQuant non è solo una teoria accademica, ma una soluzione pronta per la scalabilità industriale. I dati emersi dai benchmark di Google evidenziano quanto segue:
-
Riduzione della memoria: l'utilizzo della cache key-value è calato di 6 volte rispetto ai metodi standard;
-
Velocità di calcolo: su acceleratori Nvidia H100, il calcolo dei punteggi di attenzione a 4 bit è risultato 8 volte più rapido rispetto alla precisione a 32 bit;
-
Precisione del modello: i risultati hanno mostrato una perdita di qualità pari allo 0%, un traguardo quasi impossibile con le precedenti tecniche di quantizzazione;
-
Flessibilità: l'algoritmo può operare a soli 3 bit senza richiedere un nuovo addestramento (retraining) del modello esistente.
Implicazioni economiche e democratizzazione dell'AI
Dal punto di vista dell'investimento e dell'economia di scala, TurboQuant ha il potenziale per abbattere drasticamente i costi di inferenza per le aziende che integrano l'AI nei propri servizi. Una riduzione di 6x della memoria necessaria significa poter gestire carichi di lavoro sei volte superiori sullo stesso hardware, o ridurre proporzionalmente le spese per il cloud computing.
Tuttavia, il mercato guarda con particolare interesse all'IA "edge", ovvero quella residente sui dispositivi mobili. Con hardware limitato come quello degli smartphone, compressioni di questo livello permettono di far girare modelli complessi localmente, migliorando la privacy e riducendo la latenza, fattori chiave per l'adozione di massa delle nuove interfacce conversazionali nel 2026.
Analisi tecnica e prospettive sul titolo Alphabet Inc. (GOOGL)
Il titolo Alphabet (GOOGL) non ha reagito positivamente all'annuncio, confermando la continuazione del trend ribassista iniziato a febbraio. Al 26 marzo 2026, il prezzo si attesta in area 288 dollari, rompendo di fatto l'ultimo supporto tecnico in area 295$.
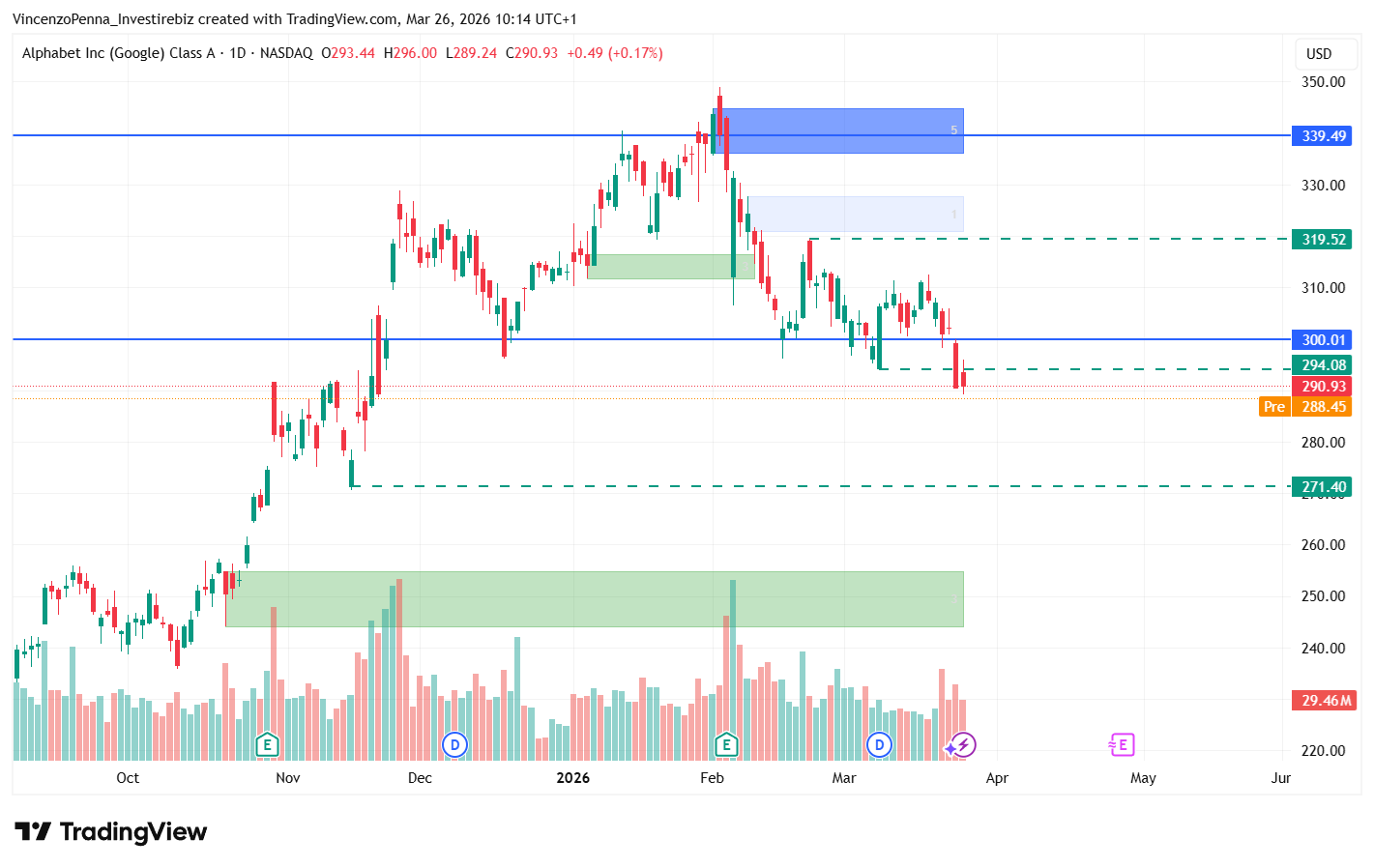 Fonte: Tradingview
Fonte: Tradingview
La capacità di Google di innovare sul fronte dell'efficienza dei costi (OPEX) non basta a rassicurare gli investitori circa la sostenibilità dei margini operativi legati ai servizi Cloud e IA.
Dal punto di vista grafico, la rottura appena subita da Alphabet, riaccende timori per un possibile sell-off di ulteriori 10-15 punti percentuali (270$-250$). Sarà fondamentale monitorare la conferenza ICLR del prossimo mese, dove i dettagli tecnici potrebbero influenzare ulteriormente la fiducia degli investitori istituzionali.
Disclaimer: File MadMar.